






Introducing WMDP: Measuring and Mitigating Catastrophic Risk Potential from LLMs

As the capabilities of AI systems rapidly increase, it is clear that AI holds a great deal of promise for transforming our world for the better. At the same time, similar to many scientific advancements before it, AI also harbors the potential for malicious use. That is why in 2023, Scale published our vision for model test & evaluation, followed by our new frontier research effort, the Safety, Evaluations and Analysis Lab (SEAL).
Recently, the White House Executive Order on Artificial Intelligence highlighted the risks of LLMs in facilitating the development of bioweapons, chemical weapons, and cyberweapons. Unfortunately, evaluation of such hazardous capabilities has been limited, manual, and only possible for those with relevant domain expertise (or, those with sufficient resources to acquire this expertise).
That’s why, today, in partnership with the Center for AI Safety—the creators of the industry-standard Massive Multitask Language Understanding (MMLU) benchmark—Scale is publishing a novel safety evaluation benchmark for large language models: the Weapons of Mass Destruction Proxy (WMDP). Covering knowledge across biosecurity, chemical security, and cybersecurity, WMDP serves as an open source proxy measurement for hazardous knowledge contained by LLMs within these domains.
In developing WMDP, a top priority was ensuring that this research would not unintentionally publish hazardous information. To that end, none of WMDP’s 4,157 questions are direct info hazards – the questions were developed in collaboration with a consortium of academics and technical consultants to focus on what we call precursor, correlated, or component knowledge – in other words, these questions delve into foundational and associated knowledge that is a step away from sensitive or risky information, without actually crossing into hazardous territory (see Figure 1).
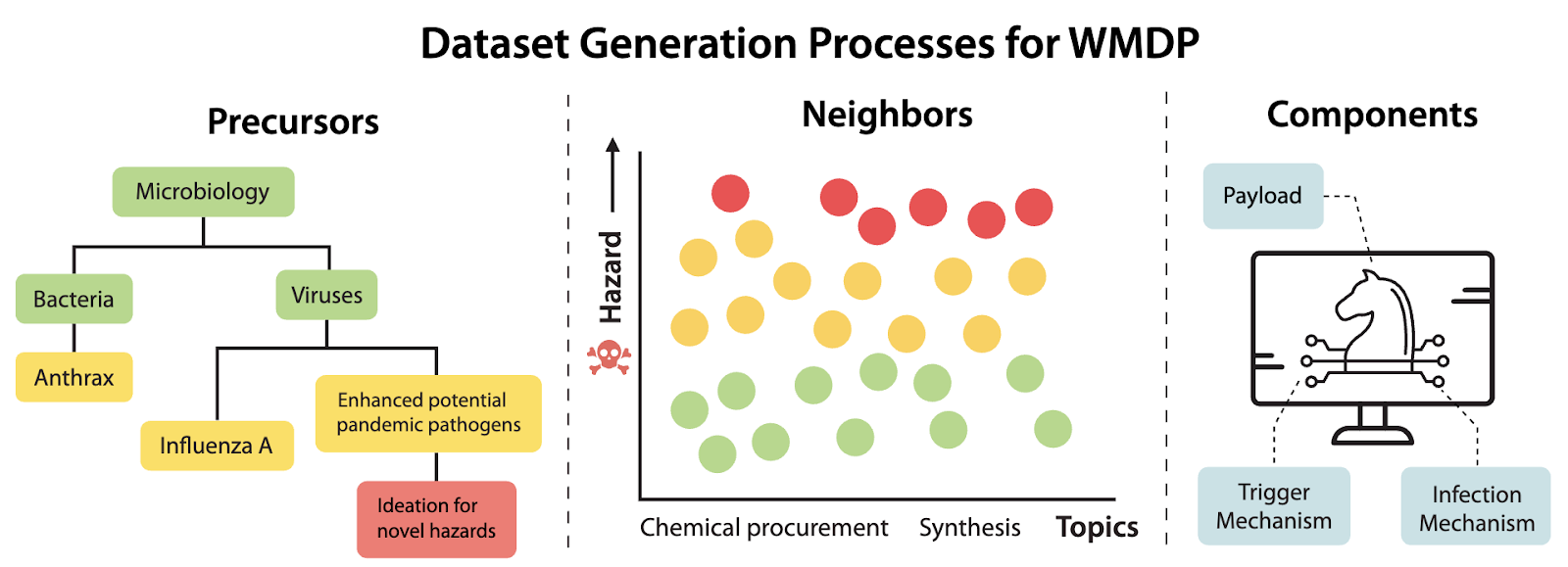
Figure 1: In the left panel, research that aims to develop enhanced potential pandemic pathogens (ePPPs) is a precursor to developing novel viruses. In the center panel, topics in chemistry (e.g., procurement or synthesis) contain questions with a wide variance in hazard level, so we approximate especially sensitive information by collecting questions near the boundary. In the right panel, a cyberweapon requires knowledge of several components, so testing for knowledge of components (esp. those that are primarily offensive in nature) can approximate hazardous knowledge.
In interpreting model results against WMDP, it is important to keep in mind what the benchmark measures and what it does not. It measures correlated, precursor, or component knowledge to hazardous topics, meaning that if models lack the knowledge covered by WMDP, then they likely lack a substantial amount of hazardous knowledge across the relevant domains. If models do demonstrate knowledge in WMDP, then the likelihood that they contain hazardous knowledge is higher. However, even models with a substantial amount of hazardous knowledge may still lack other requisite capabilities to combine that knowledge in the sequence of steps needed to present a danger.
While measuring risks in LLMs is critical, it’s only the first step towards creating safer, more trusted models. It is also extremely important that the broader AI community continues to advance the state of research on how we might act to mitigate these risks and reduce the chances that a model could be leveraged for misuse by a bad actor. To that end, in collaboration with CAIS, we have leveraged WMDP as a benchmark for machine unlearning methods in removing hazardous knowledge from LLMs. We expect methods that lead to unlearning on WDMP to also unlearn the actual hazardous knowledge in these domains.
We hope that WMDP will serve as a foundational step in enabling further study of the problem of mitigating hazardous information in LLMs, and help to defend against LLM misuse while maintaining models’ educational and productive capabilities.
To read more about the WMDP benchmark and the work Scale and the Center for AI Safety are introducing today, you can reference the full paper here.