
Top 4 Tools to Build Your ML Model Evaluation Pipeline

Model evaluation is one of the most important prerequisites prior to shipping an ML model. If you don’t properly evaluate your model, performance regressions might appear in production and have a direct and negative impact on your business. For example, if a faulty pedestrian detection model is deployed onto an autonomous vehicle, it can potentially cause an accident. In its most basic form, model evaluation is very straightforward, but as we discussed in our previous blog, approaches that are too simple aren’t really reliable. Therefore, most ML teams aspire to maintain a mature model evaluation pipeline in order to systematically understand model performance. A mature evaluation pipeline covers the entire lifecycle of ML development:
- Model training and re-training
- Model testing and validation
- Model performance monitoring in production
To cover all these aspects, ML teams need sophisticated tooling, which is why we assembled a list of 4 MLOps tools that we believe will help you build a great model evaluation pipeline:
Weights & Biases

Weights & Biases (W&B, for short) is a great tool for logging information and analyzing performance during model training. It is designed to track standard training metrics like loss, training dataset (“train”) accuracy, validation (“val”) dataset accuracy, GPU utilization, and more. W&B will also log your raw data like images or point clouds along with their matching predictions like bounding boxes, cuboids, and segmentation masks. Moreover, W&B supports experiment tracking. Users can log training run configurations, including sets of hyperparameters, and use these to reproduce the experiment later. Already widely adopted in the ML community, W&B is a more powerful cloud-hosted alternative to TensorBoard, especially if teams want to converge on a collaborative tool.
COCO Eval API

While there are a lot of tools available to log training and evaluation metrics, COCO’s eval API is among the handful that provide these metric definitions and implementation out of the box. Released as a toolkit for interacting with the MSCOCO dataset, the COCO eval API has now become the standard tool for many ML developers working on computer vision use cases like object detection. The API supports the calculation of IoU, precision, and recall on bounding boxes, segmentation masks, and keypoints. It also allows users to aggregate these scores—both per item and per class. Although very bare bones, the COCO eval API is a handy tool for obtaining standard metrics.
Scale Validate
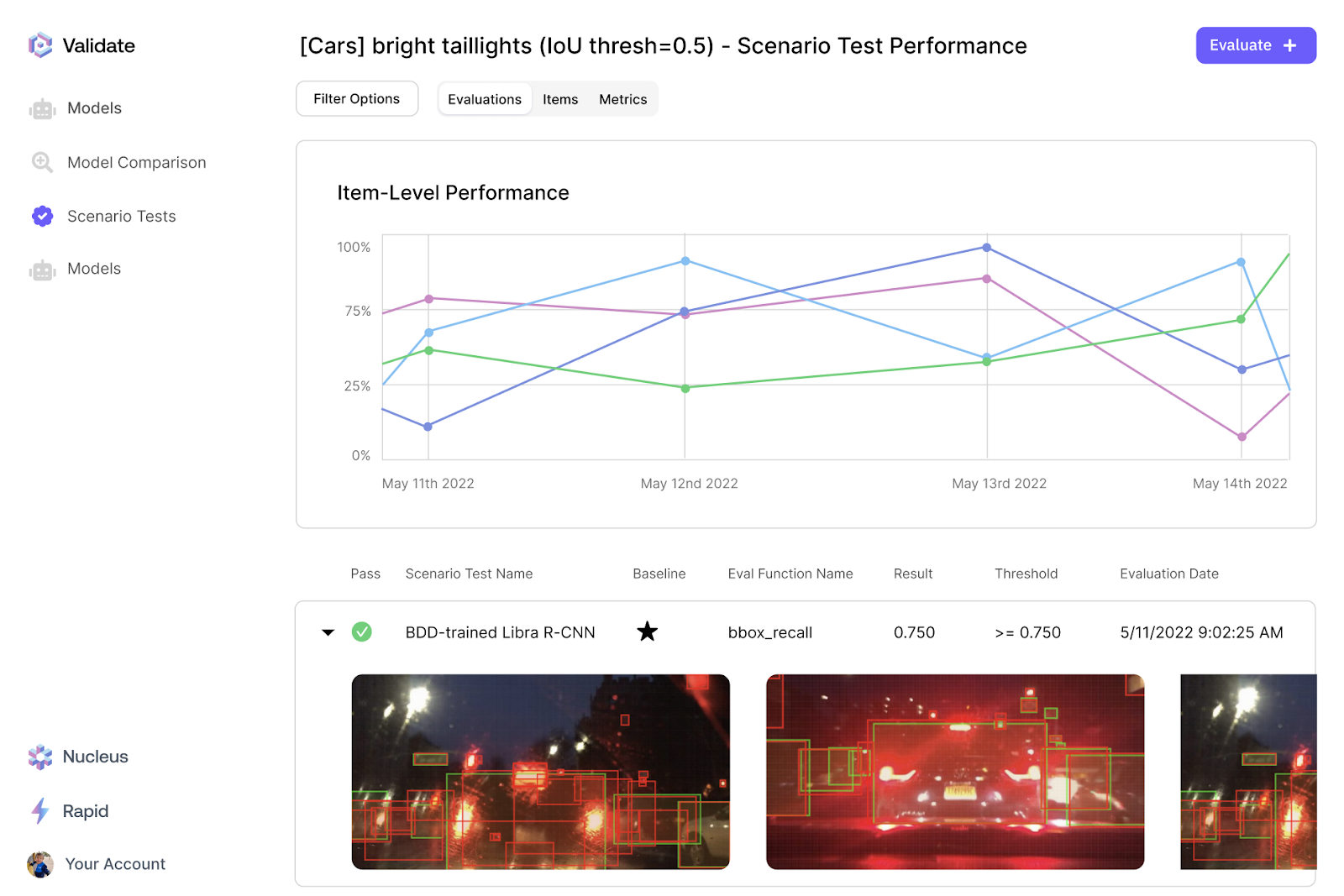
While metric computation and logging are essential, they are not sufficient to uncover the true performance of the model prior to deployment for reasons such as data inequality and comparison complexities (you can learn more here). ML teams frequently tackle these challenges using Scale Validate, which provides a structured framework for testing and comparing ML models. Validate allows you to:
- Compare models on a rich set of pre-computed metrics e.g. precision, recall, confusion matrix, IoU or mAP.
- Find underperforming slices through automatic clustering based on image embeddings and metric scores
- Set up tests on mission-critical scenarios to track progress on metrics of choice over time and catch regressions.
Through these strategies, Validate helps dissect obscure aggregate metrics into more granular insights and ensures that the model being shipped performs better not just on the aggregate but also on the more critical and rare long-tail situations.
Why Labs

After a model has been deployed to production, it is crucial to keep monitoring its performance to ensure that the model performs as expected. WhyLabs is an observability platform designed to monitor ML model performance degradation. Users can create monitors to target a particular performance metric—typically, precision, recall or F1 score. Once the monitors are set, WhyLabs tracks the metrics relative to baselines set by the user. These baselines can be based on a dynamic range, like an average metric value over a historic time interval or a static fixed value. Using these monitors, users can also set corresponding actions if the value crosses certain thresholds, like alert messages. WhyLabs can be deployed in production cloud environments including AWS and GCP, or on-premises.
Great AI applications require dependable ML models and an ML model’s dependability can’t be ascertained without foolproof evaluation. Using these tools, ML teams can build a reliable evaluation pipeline to uncover true model performance and avoid any regressions in production. Get started with Scale Validate today to uncover and fix regressions over critical scenarios.